|
A-Level organic chemistry exam revision notes on
alcohols
Part
4.1
ALCOHOLS
- naming, structure and classification
4.1 The
Molecular Structure and Nomenclature (naming)
of the homologous series of ALCOHOLS of general formula CnH2n+1OH,
diols, triols, cyclo-alcohols and epoxy compounds and some isomeric ethers
[Author
©
Dr Phil Brown PhD:
Doc Brown's advanced level organic chemistry exam revision notes
suitable for students of UK A level chemistry courses & US K12 grade
11, grade 12 and AP honors chemistry courses: The chemistry of
alcohols - naming and structure
[updated
Feb 27th 206 *]
Email doc
brown query? comment?
*
[privacy policy, cookies
and disclaimer]
Sub-index for this
alcohol chemistry page 4.1 naming and structure of alcohols
(and selected isomeric ethers)
4.1.1
Nomenclature Introduction
4.1.2
The names and structures of aliphatic alcohols CnH2n+1OH
(and isomeric ethers)
 4.1.3
Naming
chloroalcohols 4.1.3
Naming
chloroalcohols
4.1.4
Naming diols/triols
4.1.5
Naming cyclo-alcohols
 4.1.6
Naming phenols 4.1.6
Naming phenols
4.1.7
Naming epoxy compounds
4.1.8
Oxidation sequence: alcohol ==>
aldehyde/ketone ==> carboxylic
acid
 Multiple choice quiz on naming alcohols and ethers
Multiple choice quiz on naming alcohols and ethers
 Type in name
(short answer) quiz on alcohols and ethers Type in name
(short answer) quiz on alcohols and ethers
 Summary of Organic Functional Groups Notes Summary of Organic Functional Groups Notes
Simple quiz on Organic Structure Recognition
Summary of organic
chemistry functional group tests
Intermolecular forces & boiling points of
alcohols compared to other
organic molecules
The shapes
and bond angles of simple organic molecules
Summary
Doc Brown's
Chemistry Advanced Level Pre-University Chemistry Revision Study Notes for UK
KS5 A/AS GCE IB advanced level organic chemistry students US K12 grade 11 grade 12 organic chemistry The nomenclature of alcohols and ethers -
structure and names of alcohols and ethers How do we name alcohols (alkanols)? How do we name ethers? Examples of acceptable names, displayed formula of alcohols and
ether molecules via graphic
formula, molecular formula, skeletal formula, structural formula of these
homologous series of aliphatic alcohols (alkanols) including isomers of molecular formula
up to C7H16O, lower ETHER (alkoxyalkanes) functional group isomers and epoxyalkanes
Multiple choice/type
in name quiz on naming alcohols and ethers
4.1.1
A brief guide to alcohol, ether
and epoxy-alkane structure-naming-nomenclature
The names in bold are the preferred IUPAC
alcohol name.
- Introduction to the naming and structure
of alcohols and ethers.
- How do we systematically name alcohols?
molecules that contain the hydroxyl group -OH
- How do we systematically name ethers?
molecules that contain the carbon-oxygen-carbon C-O-C link
- The homologous series of alcohols have the hydroxyl
functional group
OH attached to at least one of the carbon atoms in the chain of an
aliphatic compound.
- The homologous series of saturated non-cyclic aliphatic alcohols
have the general formula CnH2n+1OH, n = 1, 2,
3, etc.
- The linear primary alcohol homologous series general
formula is: CH3(CH2)nOH, n = 0, 1, 2, 3,
etc.
- for methanol, ethanol, propan-1-ol, butan-1-ol etc.
- If the OH group is directly attached to a benzene ring , it is classified as a
phenol.
- The primary suffix name is ..ol
for alcohol and so for the longest carbon chain (alkanol) the names are
based on: 1 carbon atom, methanol; 2 carbons, ethanol; 3 carbons, propanol; 4
carbons, butanol. After these 4 preserved 'old trivial' names, the name is
'numerically' systematic e.g. 5 carbons, pentanol; 6 hexanol, 7 heptanol, 8
octanol etc.
- The 'alkyl' part of the main chain name is the parent
alkane minus the end e and adding the suffix ol to give the alcohol name.
- So, ignoring any chain position numbering needed we
get: methanol, ethanol, propanol, butanol, pentanol etc.
- In terms of abbreviated structural formula you get
the following sequence
- CH3OH, CH3CH2OH,
CH3CH2CH2OH, CH3CH2CH2CH2OH,
CH3CH2CH2CH2CH2OH
etc.
- The positions of the substituent alkyl (or other)
groups are denoted by using the lowest possible numbers for the associated
carbon atoms in the main chain e.g.
- 2-methylpropan-1-ol
 , OH at end of chain on carbon atom 1, CH3 on 2nd carbon atom.
, OH at end of chain on carbon atom 1, CH3 on 2nd carbon atom.
- 2,3-dimethylbutan-1-ol
 ,
the 1- is the lowest possible number for the hydroxyl group and 2 and 3 for
the methyl groups,
the hydroxyl alcohol functional group takes precedence over other substituent
groups such as alkyl or halogen. ,
the 1- is the lowest possible number for the hydroxyl group and 2 and 3 for
the methyl groups,
the hydroxyl alcohol functional group takes precedence over other substituent
groups such as alkyl or halogen.
- 4-methylpentan-2-ol
 , the longest carbon chain is 5, the lowest number for the OH group is 2,
but that means the lower ranking methyl group is assigned to carbon atom 4.
, the longest carbon chain is 5, the lowest number for the OH group is 2,
but that means the lower ranking methyl group is assigned to carbon atom 4.
- If there is more than one 'type' of substituent e.g.
using the prefixes: methyl… and ethyl.. etc., they are written out in
alphabetical order,
- BUT di, tri are ignored in using this rule, so ethyl
comes before methyl which comes before propyl etc. and it does not matter
whether its methyl/dimethyl or ethyl/diethyl etc.
- Alcohols are classified according to the atoms/groups
attached to the carbon of the hydroxyl group
 or
or  Primary alcohols ('prim', 1o) have the
structure R-CH2-OH, R = H, alkyl or aryl i.e. apart from
methanol, they have one alkyl/aryl group attached to the C of the C-OH group
and 2 (3 in case of methanol only) H's attached to the C of the C-OH
functional group.
Primary alcohols ('prim', 1o) have the
structure R-CH2-OH, R = H, alkyl or aryl i.e. apart from
methanol, they have one alkyl/aryl group attached to the C of the C-OH group
and 2 (3 in case of methanol only) H's attached to the C of the C-OH
functional group.-
 or
or
 Secondary alcohols ('sec',
2o) have the
structure R2CH-OH, R = alkyl or aryl. i.e. they have two
alkyl/aryl groups attached to the C of the C-OH group and 1 H attached to
the C of the C-OH functional group. Secondary alcohols ('sec',
2o) have the
structure R2CH-OH, R = alkyl or aryl. i.e. they have two
alkyl/aryl groups attached to the C of the C-OH group and 1 H attached to
the C of the C-OH functional group.
-
 or
or
 Tertiary alcohols ('tert',
3o) have the
structure R3C-OH, R = alkyl or aryl. i.e. they have three
alkyl/aryl groups attached to the C of the C-OH group and no H attached to
the C of the C-OH functional group. Tertiary alcohols ('tert',
3o) have the
structure R3C-OH, R = alkyl or aryl. i.e. they have three
alkyl/aryl groups attached to the C of the C-OH group and no H attached to
the C of the C-OH functional group.
- You do come across primary, secondary and
tertiary alcohols denoted by 'degrees' i.e. 1o, 2o
and 3o.
 To sum up!
To sum up!
- Ethers are named on the basis
of the longest carbon chain with the O-R or alkoxy group, e.g. methoxy CH3O-
or ethoxy CH3CH2O- etc. treated as a substituent group
of a parent alkane.
- Alcohols and ethers with the same molecular
formula are functional group structural isomers e.g.
- the alcohol ethanol
and the ether methoxymethane
, both C2H6O
- If the position of the OH group can be varied in the
same carbon chain structure, you are dealing with positional structural
isomerism e.g.
- the alcohol propan-1-ol
 and the alcohol propan-2-ol
and the alcohol propan-2-ol  , both C3H8O
, both C3H8O
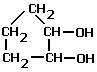
- Diol and triol structures are
named on the basis of the longest carbon chain and the suffix 'ol'. Diol and
triol means two or three hydroxyl groups in the molecule. The positions
of the OH groups is denoted with the lowest possible numbers. The prefix uses
the full parent alkane name e.g. butane….
Examples
of diols and triols
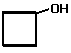
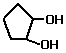
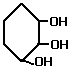
- Cycloalcohols (cycloalkanols) are named on the basis
of the number of carbon atoms in the ring (minimum 3) and the prefix 'cyclo'
and the suffix 'ol'
Examples of cyclic alcohols
- If the OH group (hydroxy) is directly
attached to a benzene ring, the molecule is classified as a 'phenol'.
- Epoxy
compounds have a -C-C-O- triangle (epoxide/oxirane ring) in their
structure which is equivalent to the simplest cyclic ether.
Examples of epoxy compounds
- Some 'old' names are quoted in (italics) though
their use should be avoided if possible [but many still used - just put one into
GOOGLE!].
- Structural isomers (structural
isomerism) are identified in the text and also whether the
alcohol or ether exhibits optical (R/S)
stereoisomerism.
Multiple choice/type
in name quiz on naming alcohols and ethers
TOP OF PAGE and
sub-index for this page
4.1.2
The names and structures of aliphatic alcohols CnH2n+1OH
(and isomeric ethers)
The names in bold are the preferred IUPAC
ketone name.
(1) The simplest alcohol is methanol
(prim)
(methyl alcohol), molecular formula of (a) 
(also the empirical formula) and four structural formulae representations:
(b) abbreviated structural formulae (c)
(d) 2D displayed formulae , (e) 3D version of the full structural formula
, (e) 3D version of the full structural formula  of methanol.
of methanol.
The latter gives a 3-dimensional structural formula impression of the molecule
methanol, the 1st simplest primary alcohol molecule, as do the 'ball and stick'
and 'space-filling' models of methanol shown below.
 AND
AND

3D ball and stick model of methanol CH3OH AND 3D space-filling model of methanol
CH3OH
 Dot and cross diagram for the methanol molecule showing the inner shell
electrons of carbon and oxygen.
Dot and cross diagram for the methanol molecule showing the inner shell
electrons of carbon and oxygen.
Carbon's electrons are 1s22s22p2,
(2.4, 4 outer valency
electrons, 4 short of a noble gas electron configuration), oxygen, 1s22s22p4, 2.6
(6 outer valency
electrons, 2 short of a noble gas electron configuration) and hydrogen just
1,1s1
Multiple choice/type
in name quiz on naming alcohols and ethers
NOTES:
(i) all the C-C-H, H-C-H, C-O-H,
C-C-O or H-C-O bond angles are all approximately 109o in all the non-cyclic alcohols or alkanols shown here or below.
(ii) From (b), the most 'shortened' structural formula, to (d), the most detailed structural formula, show increasing detail of the specific bonds and spatial arrangement of the atoms. (3)The naming of alcohols is based on the longest carbon chain and the suffix 'ol' meaning the functional group -OH (hydroxyl) attached to the carbon chain.
For alcohols with one
hydroxyl group the empirical
formula is always the same as the molecular formula.
(2) The next alcohol is ethanol
(prim) (ethyl
alcohol, 'alcohol'), molecular formula (a) , ,
five structural formulae representations of the 2ndprimary
alcohol in the homologous series of aliphatic alcohols
(b) , (c) , (c) , (d) , , (d) ,
the 2D displayed formulae (e)
of ethanol - full structural formula (all atoms and bonds shown),
and (f)
'3D'
of the full displayed structural formula
 and skeletal formula is (g) and skeletal formula is (g)
 The ball
and stick model of the ethanol molecule read as CH3-CH2-OH. The ball
and stick model of the ethanol molecule read as CH3-CH2-OH.
 The
dot and cross diagram of the ethanol molecule.
Only the outer electrons are shown in the dot
and cross diagram above. The 2 inner electrons of carbon and oxygen
are not shown. Again. carbon's electrons are 1s22s22p2,
(2.4, 4 outer valency
electrons, 4 short of noble gas configuration), oxygen, 1s22s22p4, 2.6
(6 outer valency
electrons, 2 short of noble gas configuration) and hydrogen just
1,1s1 The
dot and cross diagram of the ethanol molecule.
Only the outer electrons are shown in the dot
and cross diagram above. The 2 inner electrons of carbon and oxygen
are not shown. Again. carbon's electrons are 1s22s22p2,
(2.4, 4 outer valency
electrons, 4 short of noble gas configuration), oxygen, 1s22s22p4, 2.6
(6 outer valency
electrons, 2 short of noble gas configuration) and hydrogen just
1,1s1
Carbon's electrons are 1s22s22p2,
(2.4, 4 outer valency
electrons, 4 short of noble gas configuration), oxygen, 1s22s22p4, 2.6
(6 outer valency
electrons, 2 short of noble gas configuration) and hydrogen just
1,1s1
NOTE: The skeletal formula (below) is that of ethane plus the -OH, so the bond between the carbon chain and the hydroxyl group is shown in the skeletal formula - do NOT confuse it with a 'propane skeleton' - watch out for this in alcohols, ethers and any other structures where a H atom is replaced by a group that is NOT alkyl. The skeletal formula usually represents the bond network /\/ etc. apart from the C-H bonds.
In the 3D version of the displayed
formula the dots mean bonds to atoms behind the plane of the paper/screen,
wedges towards you mean bonds coming out from the plane of the paper/screen
and you can consider the atoms of the H-C-C-O-H sequence to be all in the
plane of the paper/screen. You also get a good impression of the bond angles
of the molecule, all of which are ~109o and NOT 90o!
for H-C-H, H-C-C, C-C-H and C-O-H.
Multiple choice/type
in name quiz on naming alcohols and ethers
(3) With the molecular formula (a), we have the first ether isomer of an alcohol. Methoxymethane
(dimethyl ether) has the structural formulae (b) , (c) , (c) , (d), (e) , (d), (e) , (f) , (f) , ,
NOTE(1) The H-C-O or C-O-C bond angles are all approximately 109 degrees (see notes for methanol at the start). (2) Ethers are named on the basis of (I)
the longest carbon chain, and (II) the -OR group (where R is alkyl), is treated as a substituent in the longest carbon chain (better illustrated with later examples). The -OR or alkoxy group is named after its carbon length
e.g. 'meth', 'eth' etc. plus an added suffix of 'oxy'.
Ethanol and
methoxymethane are functional group structural isomers of each other.
There are two structural (positional) isomers of alcohols/alkanols of molecular formula 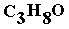 , molecules (4) and (5) , molecules (4) and (5)
(4) Propan-1-ol (prim) (1-propanol, n-propanol,
n-propyl alcohol) has the structural formulae
(a) , (b) , (b) , (c)
and full displayed formulae , (c)
and full displayed formulae
and (d) and the skeletal formula is (e) and the skeletal formula is (e) ,
the 3rd primary alcohol in the series ,
the 3rd primary alcohol in the series
NOTE a suffix number is now needed to show the position of the -OH or 'ol' functional group.
All the bond angles e.g. H-C-H, H-C-C, H-C-O, C-C-C and C-O-H
are all ~109o
Multiple choice/type
in name quiz on naming alcohols and ethers
(5) Propan-2-ol (sec) (2-propanol, isopropanol,
isopropyl alcohol) has the structural formulae
(a) , (b), (c)
and displayed formulae , , (b), (c)
and displayed formulae ,
(d) the skeletal formula is (e) the skeletal formula is (e) ,
the simplest possible secondary alcohol ,
the simplest possible secondary alcohol
Propan-1-ol and propan-2-ol are positional structural
isomers of each other.
(6) There is one ether functional group
structural isomer of two alcohols with the same molecular formula
(a). This is methoxyethane
(methyl ethyl ether or ethyl methyl ether) whose structural formulae are
(b) , (c) , (c) , (d) , (d) , ,
(e) and the skeletal formula is (f) and the skeletal formula is (f) , the functional group structural isomer of the two alcohols above. As with the isomeric alcohols, all the H-C-H, H-C-O and
C-O-C bond angles of the ether are ~109o
, the functional group structural isomer of the two alcohols above. As with the isomeric alcohols, all the H-C-H, H-C-O and
C-O-C bond angles of the ether are ~109o
Multiple choice/type
in name quiz on naming alcohols and ethers
There are four structural isomers of  which are
aliphatic alcohols - molecules (7) to (10) which are
aliphatic alcohols - molecules (7) to (10)
(7) Butan-1-ol (prim) (1-butanol, n-butanol,
n-butyl alcohol), full displayed and shortened structural formulae
(a) ,
(b) ,
(b) or (c) or (c)
and the skeletal formula is (c) ,
4th primary alcohol in the homologous series of linear aliphatic alcohols ,
4th primary alcohol in the homologous series of linear aliphatic alcohols
(8) Butan-2-ol (sec) (2-butanol, sec-butyl alcohol, shortened structural formulae (a)
or displayed formula (b) and the skeletal formula is (c) a secondary alcohol, exhibits optical (R/S) isomerism (four different
atoms/groups bound to the same central carbon atom, non-identical mirror image
forms theoretically possible)
a secondary alcohol, exhibits optical (R/S) isomerism (four different
atoms/groups bound to the same central carbon atom, non-identical mirror image
forms theoretically possible)
(9) 2-methylpropan-1-ol (prim) (2-methyl-1-propanol, isobutyl
alcohol, isobutanol), shortened structural formulae
(a) or (b) and the skeletal formula is (c) or (b) and the skeletal formula is (c) a primary alcohol
a primary alcohol
(10) 2-methylpropan-2-ol (tert) (2-methyl-2-propanol,
tert-butyl
alcohol), shortened structural formulae (a)
or (b) and the skeletal formula is (c) ,
the simplest possible tertiary alcohol ,
the simplest possible tertiary alcohol
There are three isomeric ethers, isomeric with the alcohols of molecular formula (11) to (13)
(11) ethoxyethane (diethyl ether,
'ether'), structural formulae (a) , (b) , (b) (c)
displayed formulae (c)
displayed formulae  or (d) or (d) and the skeletal formula is (e) and the skeletal formula is (e)
(12) 1-methoxypropane (methyl propyl
ether), use of prefix number now required, shortened structural formulae (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
Multiple choice/type
in name quiz on naming alcohols and ethers
(13) 2-methoxypropane, (methyl isopropyl ether) shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
So these two ethers (11) & (12) are structurally
isomeric with the four alcohols (7) to (10).
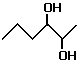
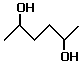
There are 8 structurally isomeric alcohols derived from the molecular formula  (14) to (21),
8 structural isomers (14) to (21),
8 structural isomers
(14) pentan-1-ol (1-pentanol, n-pentanol,
n-pentyl alcohol, n-amyl alcohol), shortened structural formula (a) or (b) or (b) , can also be written as CH3(CH2)5CH2OH, (c)
, can also be written as CH3(CH2)5CH2OH, (c)
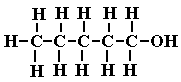 displayed
formula and (d) skeletal formula displayed
formula and (d) skeletal formula  , the 5th primary alcohol in the homologous series of aliphatic alcohols
, the 5th primary alcohol in the homologous series of aliphatic alcohols
(15) pentan-2-ol (2-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
Multiple choice/type
in name quiz on naming alcohols and ethers
(16) pentan-3-ol (3-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol
, a secondary alcohol
(17) 2-methylbutan-1-ol (2-methyl-1-butanol, 'active' amyl
alcohol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol, will exhibit optical (R/S) isomerism
, a primary alcohol, will exhibit optical (R/S) isomerism
NOTE from now on you will notice that the lowest number is for the 'highest ranking' substituent in the main carbon chain
i.e. 'ol' ranks higher than 'methyl' and uses the lowest available number first.
(18) 3-methylbutan-1-ol (3-methyl-1-butanol, isopentanol,
isoamyl alcohol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(19) 2-methylbutan-2-ol (2-methyl-2-butanol, t-amyl alcohol,
t-pentanol), shortened structural formula (a)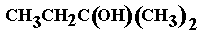 or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a tertiary alcohol
, a tertiary alcohol
(20) 3-methylbutan-2-ol
(3-methyl-2-butanol, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(21) 2,2-dimethylpropan-1-ol (2,2-dimethyl-1-propanol,
neopentyl
alcohol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
Multiple choice/type
in name quiz on naming alcohols and ethers
There are 6 isomeric ethers, also isomeric with the above 8 alcohols derived from the molecular formula (22) to (27)
(22) 1-methoxybutane, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
(23) 2-methoxybutane, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) ,
will exhibit optical (R/S) isomerism ,
will exhibit optical (R/S) isomerism
(24) 1-ethoxypropane, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
(25) 2-ethoxypropane, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
(26) 1-methoxy-2-methylpropane, shortened structural formula (a)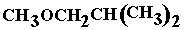 or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
(27) 2-methoxy-2-methylpropane, shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c)
Multiple choice/type
in name quiz on naming alcohols and ethers
There are 17 isomeric alcohols derived from the molecular formula 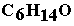 (28) to (44), ethers excluded for the moment! (28) to (44), ethers excluded for the moment!
(28) hexan-1-ol (1-hexanol, n-hexyl
alcohol), shortened structural formula (a) can also be written as CH3(CH2)4CH2OH or (b)
can also be written as CH3(CH2)4CH2OH or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol, 6th in the homologous series of linear aliphatic alcohols
, a primary alcohol, 6th in the homologous series of linear aliphatic alcohols
(29) hexan-2-ol (2-hexanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(30) hexan-3-ol (3-hexanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(31) 2-methylpentan-1-ol
(2-methyl-1-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(32) 3-methylpentan-1-ol
(3-methyl-1-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(33) 4-methylpentan-1-ol
(4-methyl-1-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(34) 2-methylpentan-2-ol
(2-methyl-2-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a tertiary alcohol
, a tertiary alcohol
(35) 3-methylpentan-2-ol
(3-methyl-2-pentanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
Multiple choice/type
in name quiz on naming alcohols and ethers
(36) 4-methylpentan-2-ol
(4-methyl-2-pentanol), shortened structural formula (a) or (b) and the skeletal formula is (c) or (b) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(37) 2-methylpentan-3-ol
(2-methyl-3-pentanol), shortened structural formula (a) or (b) or (b)  and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(38) 3-methylpentan-3-ol
(3-methyl-3-pentanol), shortened structural formula (a)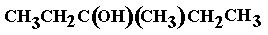 or (b) and the skeletal formula is (c) or (b) and the skeletal formula is (c) , a tertiary alcohol
, a tertiary alcohol
(39) 2,2-dimethylbutan-1-ol
(2,2-dimethyl-1-butanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
Multiple choice/type
in name quiz on naming alcohols and ethers
(40) 2,3-dimethylbutan-1-ol
(2,3-dimethyl-1-butanol), shortened structural formula (a) or (b) and the skeletal formula is (c) or (b) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(41) 3,3-dimethylbutan-1-ol
(2,2-dimethyl-1-butanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
(42) 2,3-dimethylbutan-2-ol
(2,3-dimethyl-2-butanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a tertiary alcohol
, a tertiary alcohol
(43) 3,3-dimethylbutan-2-ol
(3,3-dimethyl-2-butanol), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a secondary alcohol, will exhibit optical (R/S) isomerism
, a secondary alcohol, will exhibit optical (R/S) isomerism
(44) 2-ethylbutan-1-ol (name does not fit in with longest carbon chain rule, but a logical
and acceptable name to use), shortened structural formula (a) or (b) or (b) and the skeletal formula is (c) and the skeletal formula is (c) , a primary alcohol
, a primary alcohol
Multiple choice/type
in name quiz on naming alcohols and ethers
TOP OF PAGE and
sub-index for this page
4.1.3
Examples of aliphatic 'chloroalcohols'
Here, as in alkanes, the halogen atoms
are denoted by the prefix 'halo' ... fluoro, chloro, bromo and iodo,
which itself is prefixed by the minimum number denoting the position of
the halogen atom in the main carbon chain.
BUT, the 'ol' group still has the lowest
number in the carbon, which might mean a 'raised' number for a substituent
group!
The classification of the
alcohol is unchanged and they are higher ranking groups than 'halo'
substituents - so they have 'lowest number' precedence over a lower ranking
group.
1.  chloroethanol or 2-chloroethanol (1. based on C2H5OCl),
primary alcohol
chloroethanol or 2-chloroethanol (1. based on C2H5OCl),
primary alcohol
2.  2-chloropropan-1-ol,
primary alcohol, will exhibit optical (R/S) isomerism
2-chloropropan-1-ol,
primary alcohol, will exhibit optical (R/S) isomerism
(2. to 4. based on isomers of C3H7OCl)
You get optical (R/S) isomers, when there
are 4 different groups attached to the same carbon atom, known as the
'chiral' carbon. It means you can have non-superimposable mirror image forms
of the molecule.
See Part
14.3
Stereoisomerism - R/S Optical Isomerism
3.  3-chloropropan-1-ol, primary alcohol
(NOT 1-chloropropan-1-ol OR 1-chloropropan-3-ol)
3-chloropropan-1-ol, primary alcohol
(NOT 1-chloropropan-1-ol OR 1-chloropropan-3-ol)
4.  1-chloropropan-2-ol, secondary alcohol, will exhibit optical (R/S)
isomerism
1-chloropropan-2-ol, secondary alcohol, will exhibit optical (R/S)
isomerism
5.  2-chlorobutan-1-ol, primary alcohol, will
exhibit optical (R/S) isomerism
2-chlorobutan-1-ol, primary alcohol, will
exhibit optical (R/S) isomerism
(5. to 13. based on isomers of C4H9OCl)
6.  3-chlorobutan-1-ol, primary alcohol, will
exhibit optical (R/S) isomerism
3-chlorobutan-1-ol, primary alcohol, will
exhibit optical (R/S) isomerism
7.  4-chlorobutan-1-ol, primary alcohol
4-chlorobutan-1-ol, primary alcohol
8.  1-chlorobutan-2-ol, secondary alcohol
1-chlorobutan-2-ol, secondary alcohol
9.  3-chlorobutan-2-ol, secondary alcohol, will
exhibit optical (R/S) isomerism
3-chlorobutan-2-ol, secondary alcohol, will
exhibit optical (R/S) isomerism
10.  4-chlorobutan-2-ol, secondary alcohol, will
exhibit optical (R/S) isomerism
4-chlorobutan-2-ol, secondary alcohol, will
exhibit optical (R/S) isomerism
11.  1-chloro-2-methylpropan-2-ol, tertiary alcohol
1-chloro-2-methylpropan-2-ol, tertiary alcohol
12.  2-chloro-2-methylpropan-1-ol, primary
alcohol
2-chloro-2-methylpropan-1-ol, primary
alcohol
13.  3-chloro-2-methylpropan-1-ol, primary
alcohol, will exhibit optical (R/S) isomerism
3-chloro-2-methylpropan-1-ol, primary
alcohol, will exhibit optical (R/S) isomerism
Multiple choice/type
in name quiz on naming alcohols and ethers
formula keywords: how to name
naming nomenclature empirical molecular formula graphic formula displayed
formula skeletal formula structural isomers isomerism Nomenclature Introduction
primary prim secondary sec tertiary tert alcohols The names and structures of aliphatic alcohols CnH2n+1OH and isomeric ethers
Naming Chloroalcohols CH4O CH3OH
CH3-OH C2H6O C2H5OH CH3CH2OH CH3-CH2-OH CH3OCH3 CH3-O-CH3 C3H8O
C2H5CH2OH C3H7OH CH3CH2CH2OH CH3-CH2-CH2-OH CH3CH2OCH3 CH3OCH2CH3 CH3-O-CH2CH3 CH3-CH2-O-CH3 C4H10O
C4H9OH C3H7CH2OH CH3CH2CH2CH2OH C5H11OH C5H12O
C6H13OH C6H14O C7H15OH C7H16O
chemistry revision notes structure of alcohols & ethers AS AQA GCE A
level chemistry how do you name alcohols & ethers AS Edexcel GCE A level
chemistry alcohol and ether nomenclature rules AS OCR GCE A level
chemistry what is the molecular structure of alcohols and ethers? AS
Salters GCE A level chemistry how to work out isomers of alcohols and
ethers US grades 11 & 12 chemistry IUPAC naming of alcohols & ethers
notes for revising alcohols & ethers |





 ,
,  ,
, 
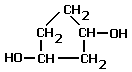 ,
, 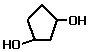
 ,
, 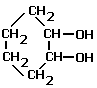 ,
, 
 ,
, 
 ,
, 
 ,
, 
 ,
, 
 ,
, 
 2-chlorophenol,
2-chlorophenol,  2-hydroxybenzoic acid,
2-hydroxybenzoic acid, 2-hydoxyphenylethanone,
2-hydoxyphenylethanone,
 methyl
2-hydoxybenzoate,
methyl
2-hydoxybenzoate, phenylmethanol (benzyl alcohol), a primary alcohol
phenylmethanol (benzyl alcohol), a primary alcohol 3-methylphenol, a phenol, NOT an alcohol
3-methylphenol, a phenol, NOT an alcohol methoxybenzene (anisole)
methoxybenzene (anisole) 1-phenylethanol,
a primary alcohol (note the substituent is on the carbon of the OH group)
1-phenylethanol,
a primary alcohol (note the substituent is on the carbon of the OH group)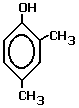 and the ether,
and the ether, ethoxybenzene (phenetole)
ethoxybenzene (phenetole) ==>
==>
 ,
propan-2-ol ==> propanone
,
propan-2-ol ==> propanone